


Objetivo
En un contexto ASR donde la mayoría de fenómenos están estudiados para las lenguas más generalizadas, el presente trabajo busca plantear una solución para el code-switching, fenómeno por el cual un hablante políglota alterna entre los diferentes idiomas que domina a lo largo de su discurso, en contextos intersentenciales donde el hablante alterna de idioma entre oraciones, típicamente a raíz de diferencias sintácticas oracionales de las lenguas que domina.
Para ello, se plantea el fine-tuning de Whisper, tecnología ampliamente utilizada en materia de transcripción de audios, para entrenar en profundidad sus modelos en los diferentes idiomas que conforman el fenómeno del code-switching en el hablante, y crear una arquitectura que permita reforzar la transcripción para idiomas que no tengan tanta cobertura.
En concreto, el presente trabajo propone una arquitectura para el caso de uso del code-switching entre el castellano y el euskera, donde ambos idiomas presentan estructuras sintácticas diferentes y el cambio de idioma no suele suponer una pérdida de significado en el mensaje.
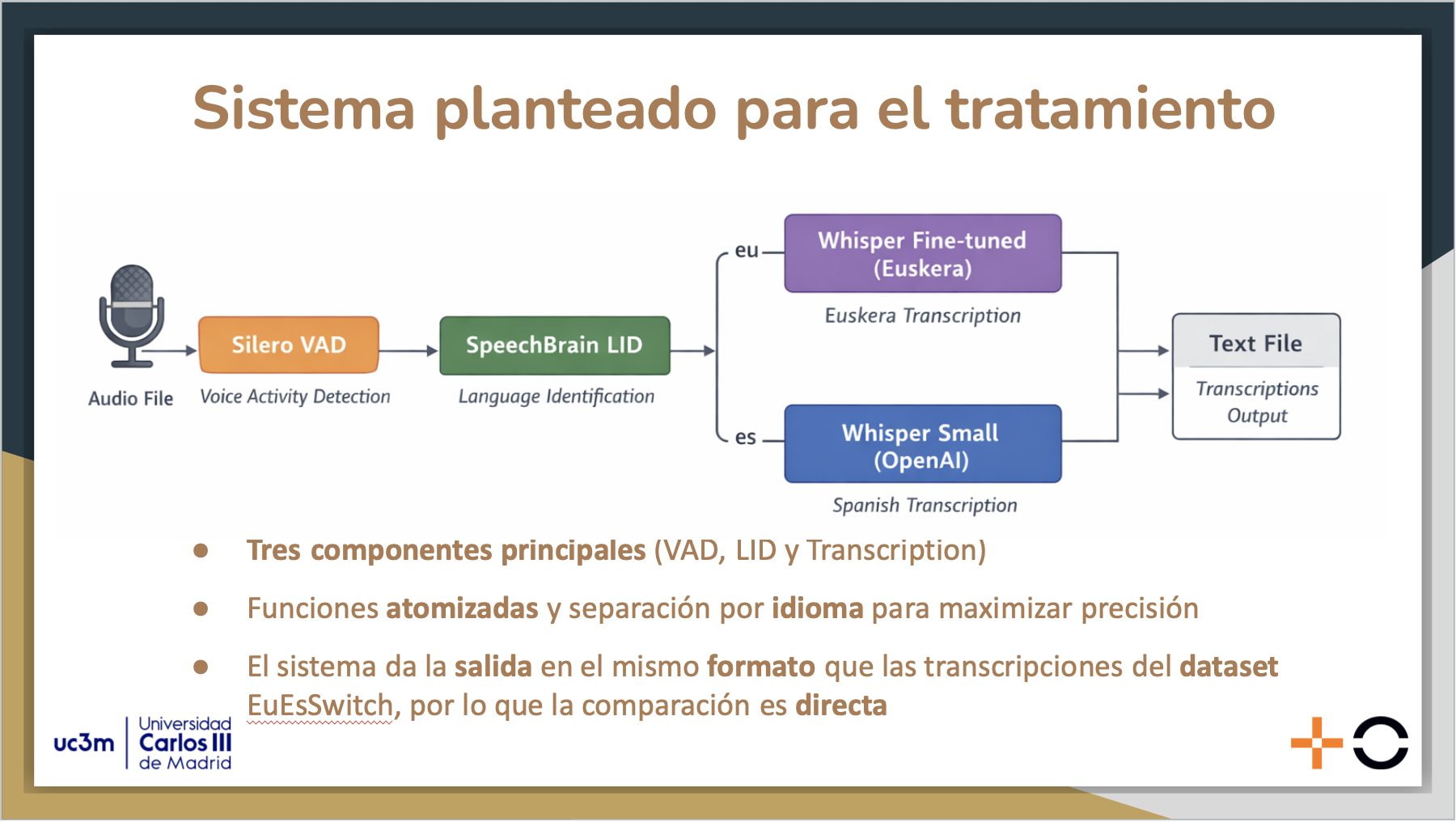
Esta arquitectura comienza con dos bloques que tratan adecuadamente el audio para maximizar la precisión del mismo en cada uno de sus segmentos: uno de VAD, haciendo uso de Silero VAD, para dividir el audio en aquellos segmentos donde existe actividad sonora; seguido de un bloque de LID, donde se busca identificar el idioma de cada uno de estos segmentos de audio para poder realizar una transcripción adaptada al idioma correspondiente.
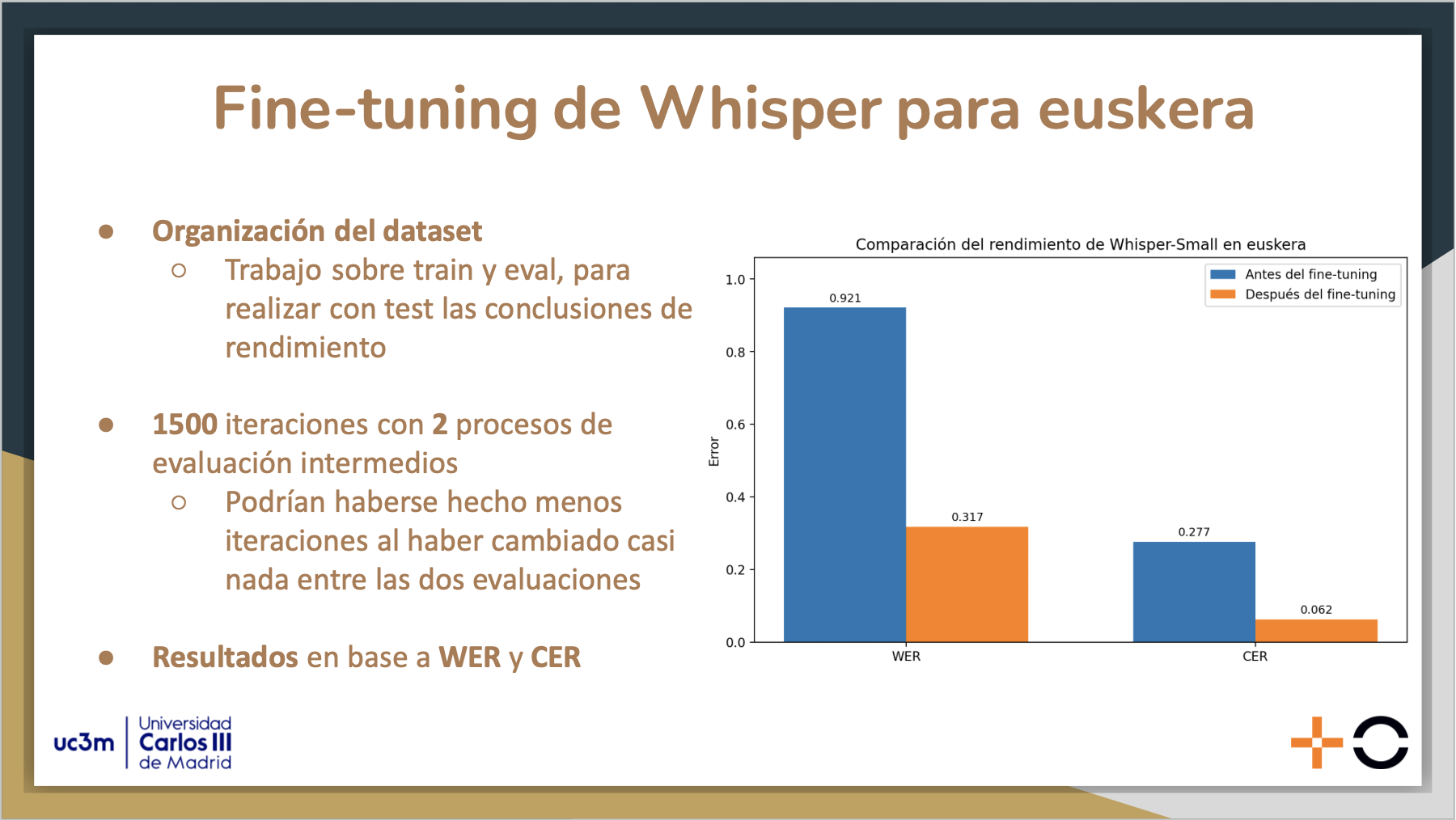
Una vez se tienen los segmentos divididos y etiquetados por idioma, se realiza una transcripción específica para el euskera en un modelo finetuneado de Whisper, manteniendo para el castellano el modelo base (debido a que tiene suficiente cobertura) para luego reunir las transcripciones de cada uno de los segmentos en un archivo de texto final.
Todo esto se realiza en base a dos datasets, uno para el fine-tuning, obtenido de la plataforma Mozilla Common Voice, mientras que el segundo es para la validación de arquitectura, sintético y con audios code-switcheados respetando la estructura intersentencial que planteamos resolver dentro del trabajo.

TRABAJO FIN DE GRADO DE:
JAVIER RAMÍREZ ZARZOSO
Experiencia Académica
- Doble Grado en Ingeniería Informática y Administración y Dirección de Empresas, Universidad Carlos III de Madrid (septiembre 2021 – julio 2026)
- Google Cloud Data Analyst Certificate (junio – julio 2025)
Experiencia Laboral
- Machine Learning Researcher – Universidad Carlos III de Madrid en colaboración con Grupo MasOrange (septiembre 2025 — junio 2026)
- Machine Learning Researcher – Universidad Carlos III de Madrid en colaboración con MARVISION – Proyecto DEIMOS (enero 2025 – julio 2025)
- Monitor de tenis (julio 2019 — agosto 2020)
Habilidades técnicas
- Lenguajes de programación: Python, C/C++, SQL, HTML/CSS, JavaScript.
- Librerías de desarrollo: Pandas, OpenCV, Numpy, PyTorch, Keras, Sci-kit Learn.
- Plataformas Cloud: Google Cloud.
- Frameworks: GitHub, GitLab.